Wasmtime 35 Brings AArch64 Support in Winch
Wasmtime is a fast, secure, standards compliant and lightweight WebAssembly (Wasm) runtime.
As of Wasmtime 35, Winch supports AArch64 for Core Wasm proposals, along with additional Wasm proposals like the Component Model and Custom Page Sizes.
Embedders can configure Wasmtime to use either Cranelift or Winch as the Wasm compiler depending on the use-case: Cranelift is an optimizing compiler aiming to generate fast code. Winch is a ‘baseline’ compiler, aiming for fast compilation and low-latency startup.
This blog post will cover the main changes needed to accommodate support for AArch64 in Winch.
Quick Tour of Winch’s Architecture
To achieve its low-latency goal, Winch focuses on converting Wasm code to assembly code for the target Instruction Set Architecture (ISA) as quickly as possible. Unlike Cranelift, Winch’s architecture intentionally avoids using an intermediate representation or complex register allocation algorithms in its compilation process. For this reason, baseline compilers are also referred to as single-pass compilers.
Winch’s architecure can be largely divided into two parts which can be classified as ISA-agnostic and ISA-specific.
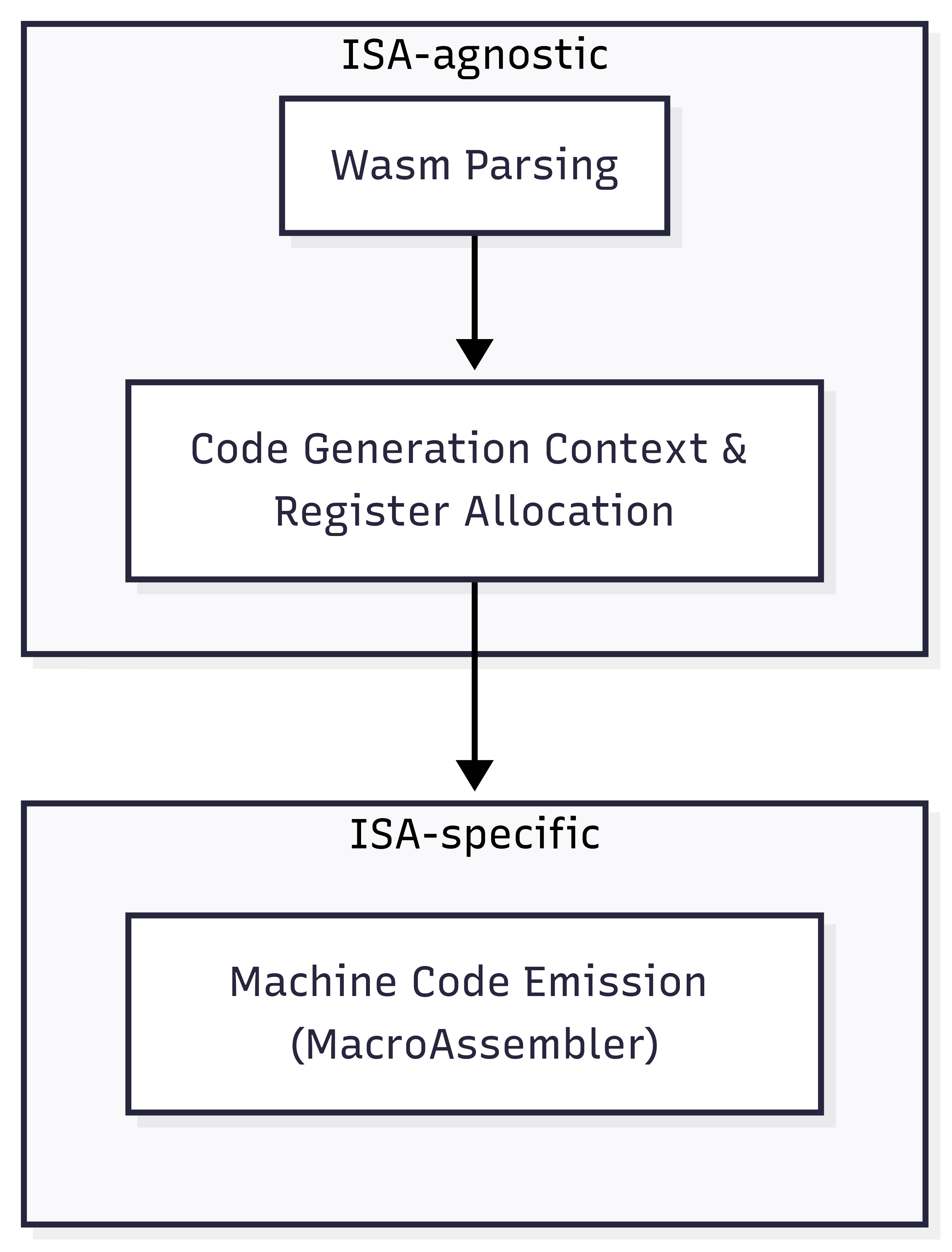
Adding support for AArch64 to Winch involved adding a new
implementation of the MacroAssembler trait, which is ultimately in
charge of emitting AArch64 assembly. Winch’s ISA-agnostic components
remained unchanged, and shared with the existing x86_64
implementation.
Winch’s code generation context implements
wasmparser’s
VisitOperator
trait, which requires defining handlers for each Wasm opcode:
fn visit_i32_const() -> Self::Output {
// Code generation starts here.
}
When an opcode handler is invoked, the Code Generation Context prepares all the necessary values and registers, followed by the machine code emission of the sequence of instructions to represent the Wasm instruction in the target ISA.
Last but not least, the register allocator algorithm uses a simple round robin approach over the available ISA registers. When a requested register is unavailable, all the current live values at the current program point are saved to memory (known as value spilling), thereby freeing the requested register for immediate use.
Emitting AArch64 Assembly
Shadow Stack Pointer (SSP)
AArch64 defines very specific restrictions with regards to the usage of the stack pointer register (SP). Concretely, SP must be 16-byte aligned whenever it is used to address stack memory. Given that Winch’s register allocation algorithm requires value spilling at arbitrary program points, it can be challenging to maintain such alignment.
AArch64’s SP requirement states that SP must be 16-byted when addressing stack memory, however it can be unaligned if not used to address stack memory and doesn’t prevent using other registers for stack memory addressing, nor it states that these other registers be 16-byte aligned. To avoid opting for less efficient approaches like overallocating memory to ensure alignment each time a value is saved, Winch’s architecture employs a shadow stack pointer approach.
Winch’s shadow stack pointer approach defines x28 as the base register
for stack memory addressing, enabling:
- 8-byte stack slots for live value spilling.
- 8-byte aligned stack memory loads.
Signal handlers
Wasmtime can be configured to leverage signals-based traps to detect exceptional situations in Wasm programs e.g., an out-of-bounds memory access. Traps are synchronous exceptions, and when they are raised, they are caught and handled by code defined in Wasmtime’s runtime. These handlers are Rust functions compiled to the target ISA, following the native calling convention, which implies that whenever there is a transition from Winch generated code to a signal handler, SP must be 16-byte aligned. Note that even though Wasmtime can be configured to avoid signals-based traps, Winch does not support such option yet.
Given that traps can happen at arbitrary program points, Winch’s approach to ensure 16-byte alignment for SP is two-fold:
- Emit a series of instructions that will correctly align SP before each potentially-trapping Wasm instruction. Note that this could result in overallocation of stack memory if SP is not 16-byte aligned.
- Exclusively use SSP as the canonical stack pointer value, copying the value of SSP to SP after each allocation/deallocation. This maintains the SP >= SSP invariant, which ensures that SP always reflects an overapproximation of the consumed stack space and it allows the generated code to save an extra move instruction, if overallocation due to alignment happens, as described in the previous point.
It’s worth noting that the approach mentioned above doesn’t take into
account asynchronous exceptions, also known as interrupts. Further
testing and development is needed in order to ensure that Winch
generated code for AArch64 can correctly handle interrupts e.g.,
SIGALRM.
Immediate Value Handling
To minimize register pressure and reduce the need for spilling values,
Winch’s instruction selection prioritizes emitting instructions that
support immediate operands whenever possible, such as mov x0,
#imm. However, due to the fixed-width instruction encoding in AArch64
(which always uses 32-bit instructions), encoding large immediate
values directly within a single instruction can sometimes be
impossible. In such cases, the immediate is first loaded into an
auxiliary register—often a “scratch” or temporary register—and then
used in subsequent instructions that require register operands.
Scratch registers offer the advantage that they are not tracked by the register allocator, reducing the possibility of register allocator induced spills. However, they should be used sparingly and only for short-lived operations.
AArch64’s fixed 32-bit instruction encoding imposes stricter limits on the size of immediate values that can be encoded directly, unlike other ISAs supported by Winch, such as x86_64, which support variable-length instructions and can encode larger immediates more easily.
Before supporting AArch64, Winch’s ISA-agnostic component assumed a single scratch register per ISA. While this worked well for x86_64, where most instructions can encode a broad range of immediates directly, it proved problematic for AArch64. Specifically, for instruction sequences involving instructions with immediates in which the scratch register was previously acquired.
Consider the following snippet from Winch’s ISA-agnostic code for computing a Wasm table element address:
// 1. Load index into the scratch register.
masm.mov(scratch.writable(), index.into(), bound_size)?;
// 2. Multiply with an immediate element size.
masm.mul(
scratch.writable(),
scratch.inner(),
RegImm::i32(table_data.element_size.bytes() as i32),
table_data.element_size,
)?;
masm.load_ptr(
masm.address_at_reg(base, table_data.offset)?,
writable!(base),
)?;
masm.mov(writable!(tmp), base.into(), ptr_size)?;
masm.add(writable!(base), base, scratch.inner().into(), ptr_size)
In step 1, the code clobbers the designated scratch register. More
critically, if the immediate passed to Masm::mul cannot be encoded
directly in the AArch64 mul instruction, the Masm::mul implementation
will load the immediate into a register—clobbering the scratch
register again—and emit a register-based multiplication instruction.
One way to address this limitation is to avoid using a scratch register for the index altogether and instead request a register from the register allocator. This approach, however, increases register pressure and potentially raises memory traffic, particularly in architectures like x86_64.
Winch’s preferred solution is to introduce an explicit scratch register allocator that provides a small pool of scratch registers (e.g., x16 and x17 in AArch64). By managing scratch registers explicitly, Winch can safely allocate and use them without risking accidental clobbering, especially when generating code for architectures with stricter immediate encoding constraints.
What’s Next
Though it wasn’t a radical change, the completeness of AArch64 in Winch marks a new stage for the compiler’s architecture, layering a more robust and solid foundation for future ISA additions.
Contributions are welcome! If you’re interested in contributing, you can:
- Start by reading Wasmtime’s contributing documentation
- Checkout Winch’s project board
That’s a wrap
Thanks to everyone who contributed to the completeness of the AArch64 backend! Thanks also to Nick Fitzgerald and Chris Fallin for their feedback on early drafts of this article.